Эволюция многоядерной процессорной архитектуры Intel Core: Conroe, Kentsfield, далее по расписанию
Intel Wide Dynamic Execution
Под технологией Intel Wide Dynamic Execution подразумевается комплекс новшеств – расширенный анализ данных, спекулятивное, внеочередное исполнение команд и т.п., впервые реализованный Intel в архитектуре P6, использовавшийся в процессорах Pentium Pro, Pentium II и Pentium III. В архитектуре Intel NetBurst для этих целей использовался модуль Advanced Dynamic Execution, обеспечивавший загрузку исполнительных модулей процессора и обладающий улучшенным алгоритмом предсказания ветвлений для снижения количества неверных предсказаний ветвлений.
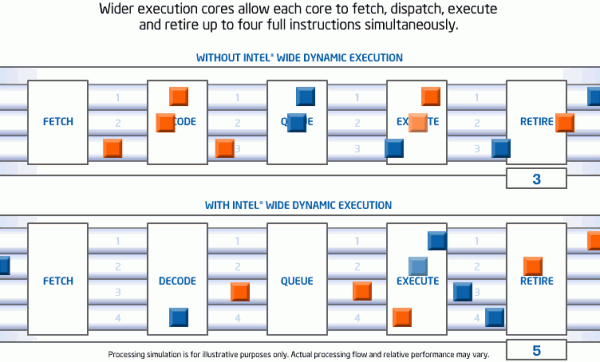
На уровне архитектуры Intel Core всё это объединено в расширенный комплекс технологий под названием Intel Wide Dynamic Execution, позволяющий обеспечить исполнение большего количества команд за один такт, благодаря чему экономится время и энергия.
Теперь каждое ядро процессора позволяет единовременно обрабатывать не три, как в архитектуре Intel NetBurst, а до четырёх команд, что выражается в 33% приросте по сравнению с предыдущими поколениями. Среди дополнительных функций, реализованных в комплексе технологий Intel Wide Dynamic Execution, также стоит упомянуть более точное предсказание ветвлений и более глубокое буферирование команд, придающее дополнительную гибкость процессу исполнения.
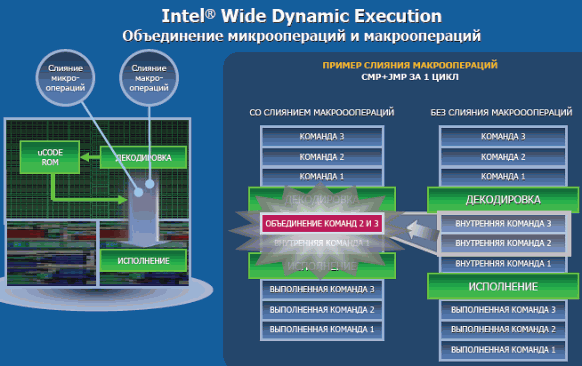
Наряду с этим Intel Wide Dynamic Execution подразумевает эффективное использование технологии макро-слияния - Macro-Fusion (Macro-OPs Fusion), объединяющей микро- и макрооперации в единые исполняемые макрооперации. Если в предыдущих поколениях процессоров Intel каждая входящая инструкция декодировалась и исполнялась отдельно, то теперь использование принципа макро-слияния в процессе декодирования команд позволяет объединять пары некоторых инструкций в единую внутреннюю инструкцию-микрооперацию (micro-op).
Исполнение двух инструкций под видом единой микрооперации позволяет снизить суммарную загрузку процессора и увеличить количество инструкций, обрабатываемых за один такт. Более того, арифметико-логические блоки (ALU, Arithmetic Logic Unit), используемые в процессорах с микроархитектурой Intel Core, также доработаны с расчётом обработки объединённых в макрооперации команд, что также отражается на общем снижении энергопотребления чипа.
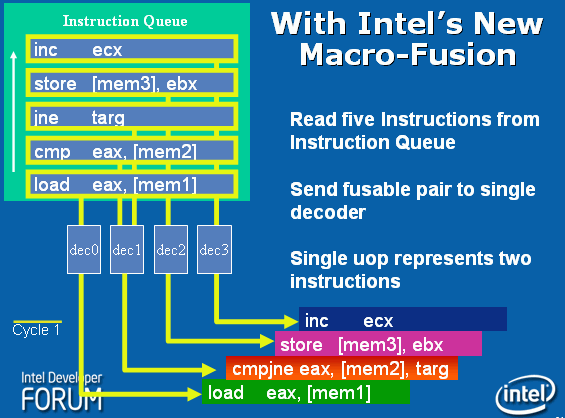
Таким образом, по данным Intel, в общем случае удаётся снизить нагрузку операций до 15% и сократить число микроопераций до 10%. Как видно на иллюстрации ниже, модули префетча (предварительной выборки) подготавливают ряд x86 команд, при этом до пяти из них могут одновременно обрабатываться четырьмя блоками декодирования. В случае возможности слияния двух команд (Macro-Fusion), появляется фактическая возможность параллельной обработки пяти инструкций за такт (единовременно может образовываться не более одной макрокоманды).
Intel Intelligent Power Capability
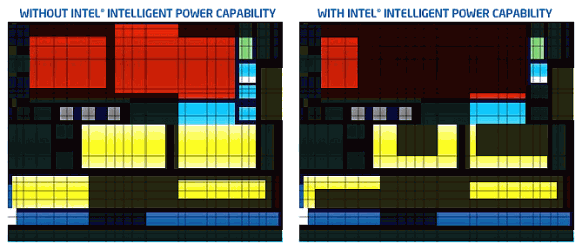
Другая инновация под сводным названием Intel Intelligent Power Capability представляет собой комплекс мер, направленных на снижение энергопотребления чипа и оптимизации общих конструктивных требований. Технологии, координирующие потребление энергии всеми исполнительными узлами процессора, включают в себя расширенные и оптимизированные по времени выборки данных функции слежения за загруженностью тех или иных логических цепей.
Что важно отметить, в архитектуре Intel Core снижение нагрузки производится не отключением неиспользуемых цепей, напротив – следящая логика Intel Intelligent Power Capability включает необходимые логические подсистемы процессора по мере их востребованности. В дополнение к этому многие внутренние шины и массивы логических узлов процессора теперь разнесены и запитываются через отдельные ключи, что позволило переводить их при обработке некоторых видов данных в дополнительный экономичный режим энергопотребления.
Основной задачей при реализации такой "точечной", адресной схемы питания было добиться быстрой реакции системы, например, при возвращении в режим полной мощности. В результате взвешенный подход при реализации возможностей Intel Intelligent Power Capability позволил добиться дополнительного снижения энергопотребления без ущерба для быстроты реагирования системы и повысить суммарную энергетическую оптимизацию архитектуры Intel Core.
Intel Advanced Smart Cache
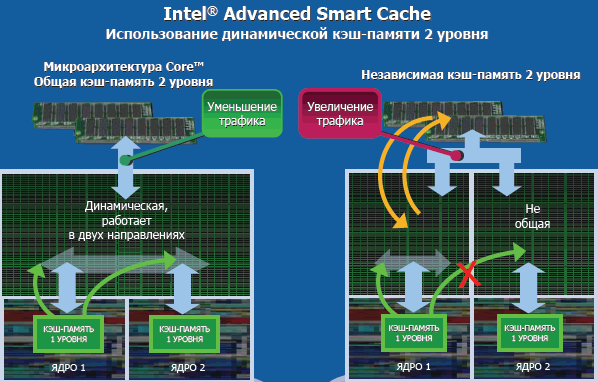
В новой архитектуре Intel Core реализована весьма и весьма эффективная модель совместного использования ядрами процессора общего кэша L2. Технология Intel Advanced Smart Cache оптимизирована таким образом, чтобы каждое ядро двухъядерного процессора могло получать доступ данным с максимальной эффективностью.
Не все современные многоядерные процессоры обладают возможностью распределения доступа к общей кэш-памяти L2. На практике это означает, что каждое ядро вынуждено оперировать с одинаковыми данными, расположенными в собственном кэше L2. Более того, простой одного из ядер при использовании раздельной схемы использования кэша L2 автоматически обозначает простой кэш-памяти L2 этого ядра, то есть, недостаточно эффективное использование ресурсов – в то время, как второе ядро, вполне возможно, "захлёбывается" без дополнительных ресурсов кэша L2.
В случае архитектуры Intel Core, когда оба ядра имеют доступ к единому кэшу L2 и обладают возможностью динамического – до 100%! - перераспределения ресурсов кэша L2 в свою пользу в зависимости от текущей загрузки, технология Multi-Core Optimized Cache позволяет добиться оптимального использования ресурсов подсистемы кэш-памяти. Дополнительный плюс Multi-Core Optimized Cache – более быстрая выборка данных из кэша.